Table of Contents
MySQL supports several storage engines that act as handlers for different table types. MySQL storage engines include both those that handle transaction-safe tables and those that handle non-transaction-safe tables:
The original storage engine was
ISAM, which managed non-transactional tables. This engine has been replaced byMyISAMand should no longer be used. It is deprecated in MySQL 4.1, and is removed in subsequent MySQL release series.In MySQL 3.23.0, the
MyISAMandHEAPstorage engines were introduced.MyISAMis an improved replacement forISAM. TheHEAPstorage engine provides in-memory tables. TheMERGEstorage engine was added in MySQL 3.23.25. It allows a collection of identicalMyISAMtables to be handled as a single table. All three of these storage engines handle non-transactional tables, and all are included in MySQL by default. Note that theHEAPstorage engine has been renamed theMEMORYengine.The
InnoDBandBDBstorage engines that handle transaction-safe tables were introduced in later versions of MySQL 3.23. Both are available in source distributions as of MySQL 3.23.34a.BDBis included in MySQL-Max binary distributions on those operating systems that support it.InnoDBalso is included in MySQL-Max binary distributions for MySQL 3.23. Beginning with MySQL 4.0,InnoDBis included by default in all MySQL binary distributions. In source distributions, you can enable or disable either engine by configuring MySQL as you like.The
EXAMPLEstorage engine was added in MySQL 4.1.3. It is a “stub” engine that does nothing. You can create tables with this engine, but no data can be stored in them or retrieved from them. The purpose of this engine is to serve as an example in the MySQL source code that illustrates how to begin writing new storage engines. As such, it is primarily of interest to developers.NDB Clusteris the storage engine used by MySQL Cluster to implement tables that are partitioned over many computers. It is available in source code distributions as of MySQL 4.1.2 and binary distributions as of MySQL-Max 4.1.3.The
ARCHIVEstorage engine was added in MySQL 4.1.3. It is used for storing large amounts of data without indexes in a very small footprint.The
CSVstorage engine was added in MySQL 4.1.4. This engine stores data in text files using comma-separated-values format.The
BLACKHOLEstorage engine was added in MySQL 4.1.11. This engine accepts but does not store data and retrievals always return an empty set.
This chapter describes each of the MySQL storage engines except for
InnoDB and NDB Cluster, which
are covered in Chapter 15, The InnoDB Storage Engine and
Chapter 16, MySQL Cluster.
When you create a new table, you can tell MySQL what type of table
to create by adding an ENGINE or
TYPE table option to the CREATE
TABLE statement:
CREATE TABLE t (i INT) ENGINE = INNODB; CREATE TABLE t (i INT) TYPE = MEMORY;
ENGINE is the preferred term, but cannot be used
before MySQL 4.0.18. TYPE is available beginning
with MySQL 3.23.0, the first version of MySQL for which multiple
storage engines were available.
If you omit the ENGINE or TYPE
option, the default storage engine is used. Normally this is
MyISAM, but you can change it by using the
--default-storage-engine or
--default-table-type server startup option, or by
setting the storage_engine or
table_type system variable.
When MySQL is installed on Windows using the MySQL Configuration
Wizard, the InnoDB storage engine is the default
instead of MyISAM. See
Section 2.3.5.1, “Introduction”.
To convert a table from one type to another, use an ALTER
TABLE statement that indicates the new type:
ALTER TABLE t ENGINE = MYISAM; ALTER TABLE t TYPE = BDB;
See Section 13.1.5, “CREATE TABLE Syntax” and
Section 13.1.2, “ALTER TABLE Syntax”.
If you try to use a storage engine that is not compiled in or that
is compiled in but deactivated, MySQL instead creates a table of
type MyISAM. This behavior is convenient when you
want to copy tables between MySQL servers that support different
storage engines. (For example, in a replication setup, perhaps your
master server supports transactional storage engines for increased
safety, but the slave servers use only non-transactional storage
engines for greater speed.)
This automatic substitution of the MyISAM table
type when an unavailable type is specified can be confusing for new
MySQL users. In MySQL 4.1, a warning is generated when a table type
is automatically changed.
MySQL always creates an .frm file to hold the
table and column definitions. The table's index and data may be
stored in one or more other files, depending on the table type. The
server creates the .frm file above the storage
engine level. Individual storage engines create any additional files
required for the tables that they manage.
A database may contain tables of different types.
Transaction-safe tables (TSTs) have several advantages over non-transaction-safe tables (NTSTs):
They are safer. Even if MySQL crashes or you get hardware problems, you can get your data back, either by automatic recovery or from a backup plus the transaction log.
You can combine many statements and accept them all at the same time with the
COMMITstatement (if autocommit is disabled).You can execute
ROLLBACKto ignore your changes (if autocommit is disabled).If an update fails, all of your changes are reverted. (With non-transaction-safe tables, all changes that have taken place are permanent.)
Transaction-safe storage engines can provide better concurrency for tables that get many updates concurrently with reads.
Although MySQL supports several transaction-safe storage engines,
for best results, you should not mix different table types within a
transaction. For information about the problems that can occur if
you do this, see Section 13.4.1, “START TRANSACTION, COMMIT, and ROLLBACK Syntax”.
Note that to use the InnoDB storage engine in
MySQL 3.23, you must configure at least the
innodb_data_file_path startup option. In 4.0 and
up, InnoDB uses default configuration values if
you specify none. See Section 15.4, “InnoDB Configuration”.
Non-transaction-safe tables have several advantages of their own, all of which occur because there is no transaction overhead:
Much faster
Lower disk space requirements
Less memory required to perform updates
You can combine transaction-safe and non-transaction-safe tables in the same statements to get the best of both worlds. However, within a transaction with autocommit disabled, changes to non-transaction-safe tables still are committed immediately and cannot be rolled back.
MyISAM is the default storage engine as of
MySQL 3.23. It is based on the ISAM code but
has many useful extensions.
Each MyISAM table is stored on disk in three
files. The files have names that begin with the table name and
have an extension to indicate the file type. An
.frm file stores the table definition. The
data file has an .MYD
(MYData) extension. The index file has an
.MYI (MYIndex) extension.
To specify explicitly that you want a MyISAM
table, indicate that with an ENGINE or
TYPE table option:
CREATE TABLE t (i INT) ENGINE = MYISAM; CREATE TABLE t (i INT) TYPE = MYISAM;
Normally, the ENGINE or TYPE
option is unnecessary; MyISAM is the default
storage engine unless the default has been changed.
You can check or repair MyISAM tables with the
myisamchk utility. See
Section 5.8.5.6, “Using myisamchk for Crash Recovery”. You can also compress
MyISAM tables with
myisampack to take up much less space. See
Section 8.2, “myisampack — Generate Compressed, Read-Only MyISAM Tables”.
The following characteristics of the MyISAM
storage engine are improvements over the older
ISAM engine:
All data values are stored with the low byte first. This makes the data machine and operating system independent. The only requirement for binary portability is that the machine uses two's-complement signed integers (as every machine for the last 20 years has) and IEEE floating-point format (also totally dominant among mainstream machines). The only area of machines that may not support binary compatibility are embedded systems, which sometimes have peculiar processors.
There is no big speed penalty for storing data low byte first; the bytes in a table row normally are unaligned and it doesn't take that much more power to read an unaligned byte in order than in reverse order. Also, the code in the server that fetches column values is not time critical compared to other code.
Large files (up to 63-bit file length) are supported on filesystems and operating systems that support large files.
Dynamic-sized rows are much less fragmented when mixing deletes with updates and inserts. This is done by automatically combining adjacent deleted blocks and by extending blocks if the next block is deleted.
The maximum number of indexes per table is 64 (32 before MySQL 4.1.2). This can be changed by recompiling. The maximum number of columns per index is 16.
The maximum key length is 1000 bytes (500 before MySQL 4.1.2). This can be changed by recompiling. For the case of a key longer than 250 bytes, a larger key block size than the default of 1024 bytes is used.
BLOBandTEXTcolumns can be indexed.NULLvalues are allowed in indexed columns. This takes 0-1 bytes per key.All numeric key values are stored with the high byte first to allow better index compression.
Index files are usually much smaller with
MyISAMthan withISAM. This means thatMyISAMnormally uses less system resources thanISAM, but needs more CPU time when inserting data into a compressed index.When records are inserted in sorted order (as when you are using an
AUTO_INCREMENTcolumn), the index tree is split so that the high node only contains one key. This improves space utilization in the index tree.Internal handling of one
AUTO_INCREMENTcolumn per table.MyISAMautomatically updates this column forINSERT/UPDATE. This makesAUTO_INCREMENTcolumns faster (at least 10%). Values at the top of the sequence are not reused after being deleted as they are withISAM. (When anAUTO_INCREMENTcolumn is defined as the last column of a multiple-column index, reuse of values deleted from the top of a sequence does occur.) TheAUTO_INCREMENTvalue can be reset withALTER TABLEor myisamchk.If a table has no free blocks in the middle of the data file, you can
INSERTnew rows into it at the same time that other threads are reading from the table. (These are known as concurrent inserts.) A free block can occur as a result of deleting rows or an update of a dynamic length row with more data than its current contents. When all free blocks are used up (filled in), future inserts become concurrent again.You can put the data file and index file on different directories to get more speed with the
DATA DIRECTORYandINDEX DIRECTORYtable options toCREATE TABLE. See Section 13.1.5, “CREATE TABLESyntax”.As of MySQL 4.1, each character column can have a different character set.
There is a flag in the
MyISAMindex file that indicates whether the table was closed correctly. If mysqld is started with the--myisam-recoveroption,MyISAMtables are automatically checked when opened, and are repaired if the table wasn't closed properly.myisamchk marks tables as checked if you run it with the
--update-stateoption. myisamchk --fast checks only those tables that don't have this mark.myisamchk --analyze stores statistics for portions of keys, not only for whole keys as in
ISAM.myisampack can pack
BLOBandVARCHARcolumns; pack_isam cannot.
MyISAM also supports the following features,
which MySQL will be able to use in the near future:
Support for a true
VARCHARtype; aVARCHARcolumn starts with a length stored in two bytes.Tables with
VARCHARmay have fixed or dynamic record length.VARCHARandCHARcolumns may be up to 64KB.A hashed computed index can be used for
UNIQUE. This allows you to haveUNIQUEon any combination of columns in a table. (However, you cannot search on aUNIQUEcomputed index.)
For the MyISAM storage engine, there's a
dedicated forum available on
http://forums.mysql.com/list.php?21.
The following options to mysqld can be used
to change the behavior of MyISAM tables:
--myisam-recover=modeSet the mode for automatic recovery of crashed
MyISAMtables.--delay-key-write=ALLDon't flush key buffers between writes for any
MyISAMtable.Note: If you do this, you should not use
MyISAMtables from another program (such as from another MySQL server or with myisamchk) when the table is in use. Doing so leads to index corruption.Using
--external-lockingdoes not help for tables that use--delay-key-write.
See Section 5.2.1, “mysqld Command-Line Options”.
The following system variables affect the behavior of
MyISAM tables:
bulk_insert_buffer_sizeThe size of the tree cache used in bulk insert optimization. Note: This is a limit per thread!
myisam_max_extra_sort_file_sizeUsed to help MySQL to decide when to use the slow but safe key cache index creation method. Note: This parameter is given in megabytes before MySQL 4.0.3, and in bytes as of 4.0.3.
myisam_max_sort_file_sizeDon't use the fast sort index method to create an index if the temporary file would become larger than this. Note: This parameter is given in megabytes before MySQL 4.0.3, and in bytes as of 4.0.3.
myisam_sort_buffer_sizeSet the size of the buffer used when recovering tables.
See Section 5.2.3, “Server System Variables”.
Automatic recovery is activated if you start
mysqld with the
--myisam-recover option. In this case, when the
server opens a MyISAM table, it checks
whether the table is marked as crashed or whether the open count
variable for the table is not 0 and you are running the server
with --skip-external-locking. If either of
these conditions is true, the following happens:
The table is checked for errors.
If the server finds an error, it tries to do a fast table repair (with sorting and without re-creating the data file).
If the repair fails because of an error in the data file (for example, a duplicate-key error), the server tries again, this time re-creating the data file.
If the repair still fails, the server tries once more with the old repair option method (write row by row without sorting). This method should be able to repair any type of error and has low disk space requirements.
If the recovery wouldn't be able to recover all rows from a
previous completed statement and you didn't specify
FORCE in the value of the
--myisam-recover option, automatic repair
aborts with an error message in the error log:
Error: Couldn't repair table: test.g00pages
If you specify FORCE, a warning like this is
written instead:
Warning: Found 344 of 354 rows when repairing ./test/g00pages
Note that if the automatic recovery value includes
BACKUP, the recovery process creates files
with names of the form
tbl_name-datetime.BAK
MyISAM tables use B-tree indexes. You can
roughly calculate the size for the index file as
(key_length+4)/0.67, summed over all keys.
This is for the worst case when all keys are inserted in sorted
order and the table doesn't have any compressed keys.
String indexes are space compressed. If the first index part is
a string, it is also prefix compressed. Space compression makes
the index file smaller than the worst-case figure if the string
column has a lot of trailing space or is a
VARCHAR column that is not always used to the
full length. Prefix compression is used on keys that start with
a string. Prefix compression helps if there are many strings
with an identical prefix.
In MyISAM tables, you can also prefix
compress numbers by specifying PACK_KEYS=1
when you create the table. This helps when you have many integer
keys that have an identical prefix when the numbers are stored
high-byte first.
MyISAM supports three different storage
formats. Two of them (fixed and dynamic format) are chosen
automatically depending on the type of columns you are using.
The third, compressed format, can be created only with the
myisampack utility.
When you CREATE or ALTER a
table that has no BLOB or
TEXT columns, you can force the table format
to FIXED or DYNAMIC with
the ROW_FORMAT table option. This causes
CHAR and VARCHAR columns
to become CHAR for FIXED
format, or VARCHAR for
DYNAMIC format.
Static format is the default for MyISAM
tables. It is used when the table contains no variable-length
columns (VARCHAR, BLOB,
or TEXT). Each row is stored using a fixed
number of bytes.
Of the three MyISAM storage formats, static
format is the simplest and most secure (least subject to
corruption). It is also the fastest of the on-disk formats.
The speed comes from the easy way that rows in the data file
can be found on disk: When looking up a row based on a row
number in the index, multiply the row number by the row
length. Also, when scanning a table, it is very easy to read a
constant number of records with each disk read operation.
The security is evidenced if your computer crashes while the
MySQL server is writing to a fixed-format
MyISAM file. In this case,
myisamchk can easily determine where each
row starts and ends, so it can usually reclaim all records
except the partially written one. Note that
MyISAM table indexes can always be
reconstructed based on the data rows.
General characteristics of static format tables:
CHARcolumns are space-padded to the column width. This is also true forNUMERIC, andDECIMALcolumns.Very quick.
Easy to cache.
Easy to reconstruct after a crash, because records are located in fixed positions.
Reorganization is unnecessary unless you delete a huge number of records and want to return free disk space to the operating system. To do this, use
OPTIMIZE TABLEor myisamchk -r.Usually require more disk space than for dynamic-format tables.
Dynamic storage format is used if a MyISAM
table contains any variable-length columns
(VARCHAR, BLOB, or
TEXT), or if the table was created with the
ROW_FORMAT=DYNAMIC option.
This format is a little more complex because each row has a header that indicates how long it is. One record can also end up at more than one location when it is made longer as a result of an update.
You can use OPTIMIZE TABLE or
myisamchk to defragment a table. If you
have fixed-length columns that you access or change frequently
in a table that also contains some variable-length columns, it
might be a good idea to move the variable-length columns to
other tables just to avoid fragmentation.
General characteristics of dynamic-format tables:
All string columns are dynamic except those with a length less than four.
Each record is preceded by a bitmap that indicates which columns contain the empty string (for string columns) or zero (for numeric columns). Note that this does not include columns that contain
NULLvalues. If a string column has a length of zero after trailing space removal, or a numeric column has a value of zero, it is marked in the bitmap and not saved to disk. Non-empty strings are saved as a length byte plus the string contents.Much less disk space usually is required than for fixed-length tables.
Each record uses only as much space as is required. However, if a record becomes larger, it is split into as many pieces as are required, resulting in record fragmentation. For example, if you update a row with information that extends the row length, the row becomes fragmented. In this case, you may have to run
OPTIMIZE TABLEor myisamchk -r from time to time to improve performance. Use myisamchk -ei to obtain table statistics.More difficult than static-format tables to reconstruct after a crash, because a record may be fragmented into many pieces and a link (fragment) may be missing.
The expected row length for dynamic-sized records is calculated using the following expression:
3 + (
number of columns+ 7) / 8 + (number of char columns) + (packed size of numeric columns) + (length of strings) + (number of NULL columns+ 7) / 8There is a penalty of 6 bytes for each link. A dynamic record is linked whenever an update causes an enlargement of the record. Each new link is at least 20 bytes, so the next enlargement probably goes in the same link. If not, another link is created. You can find the number of links using myisamchk -ed. All links may be removed with myisamchk -r.
Compressed storage format is a read-only format that is generated with the myisampack tool.
All MySQL distributions as of version 3.23.19 include
myisampack by default. (This version is
when MySQL was placed under the GPL.) For earlier versions,
myisampack was included only with licenses
or support agreements, but the server still can read tables
that were compressed with myisampack.
Compressed tables can be uncompressed with
myisamchk. (For the ISAM
storage engine, compressed tables can be created with
pack_isam and uncompressed with
isamchk.)
Compressed tables have the following characteristics:
Compressed tables take very little disk space. This minimizes disk usage, which is helpful when using slow disks (such as CD-ROMs).
Each record is compressed separately, so there is very little access overhead. The header for a record takes up 1 to 3 bytes depending on the biggest record in the table. Each column is compressed differently. There is usually a different Huffman tree for each column. Some of the compression types are:
Suffix space compression.
Prefix space compression.
Numbers with a value of zero are stored using one bit.
If values in an integer column have a small range, the column is stored using the smallest possible type. For example, a
BIGINTcolumn (eight bytes) can be stored as aTINYINTcolumn (one byte) if all its values are in the range from-128to127.If a column has only a small set of possible values, the column type is converted to
ENUM.A column may use any combination of the preceding compression types.
Can handle fixed-length or dynamic-length records.
The file format that MySQL uses to store data has been extensively tested, but there are always circumstances that may cause database tables to become corrupted.
Even though the MyISAM table format is very
reliable (all changes to a table made by an SQL statement are
written before the statement returns), you can still get
corrupted tables if any of the following events occur:
The mysqld process is killed in the middle of a write.
Unexpected computer shutdown occurs (for example, the computer is turned off).
Hardware failures.
You are using an external program (such as myisamchk) on a table that is being modified by the server at the same time.
A software bug in the MySQL or
MyISAMcode.
Typical symptoms of a corrupt table are:
You get the following error while selecting data from the table:
Incorrect key file for table: '...'. Try to repair it
Queries don't find rows in the table or return incomplete data.
You can check the health of a MyISAM table
using the CHECK TABLE statement, and repair
a corrupted MyISAM table with
REPAIR TABLE. When
mysqld is not running, you can also check
or repair a table with the myisamchk
command. See Section 13.5.2.3, “CHECK TABLE Syntax”,
Section 13.5.2.6, “REPAIR TABLE Syntax”, and
Section 5.8.5, “myisamchk — MyISAM Table-Maintenance Utility”.
If your tables become corrupted frequently, you should try to
determine why this is happening. The most important thing to
know is whether the table became corrupted as a result of a
server crash. You can verify this easily by looking for a
recent restarted mysqld message in the
error log. If there is such a message, it is likely that table
corruption is a result of the server dying. Otherwise,
corruption may have occurred during normal operation. This is
a bug. You should try to create a reproducible test case that
demonstrates the problem. See Section A.4.2, “What to Do If MySQL Keeps Crashing” and
Section E.1.6, “Making a Test Case If You Experience Table Corruption”.
Each MyISAM index
(.MYI) file has a counter in the header
that can be used to check whether a table has been closed
properly. If you get the following warning from CHECK
TABLE or myisamchk, it means that
this counter has gone out of sync:
clients are using or haven't closed the table properly
This warning doesn't necessarily mean that the table is corrupted, but you should at least check the table.
The counter works as follows:
The first time a table is updated in MySQL, a counter in the header of the index files is incremented.
The counter is not changed during further updates.
When the last instance of a table is closed (because of a
FLUSH TABLESoperation or because there isn't room in the table cache), the counter is decremented if the table has been updated at any point.When you repair the table or check the table and it is found to be okay, the counter is reset to zero.
To avoid problems with interaction with other processes that might check the table, the counter is not decremented on close if it was zero.
In other words, the counter can go out of sync only under these conditions:
The
MyISAMtables are copied without first issuingLOCK TABLESandFLUSH TABLES.MySQL has crashed between an update and the final close. (Note that the table may still be okay, because MySQL always issues writes for everything between each statement.)
A table was modified by myisamchk --recover or myisamchk --update-state at the same time that it was in use by mysqld.
Multiple mysqld servers are using the table and one server performed a
REPAIR TABLEorCHECK TABLEon the table while it was in use by another server. In this setup, it is safe to useCHECK TABLE, although you might get the warning from other servers. However,REPAIR TABLEshould be avoided because when one server replaces the data file with a new one, this is not signaled to the other servers.In general, it is a bad idea to share a data directory among multiple servers. See Section 5.11, “Running Multiple MySQL Servers on the Same Machine” for additional discussion.
The MERGE storage engine was introduced in
MySQL 3.23.25. It is also known as the
MRG_MyISAM engine.
A MERGE table is a collection of identical
MyISAM tables that can be used as one.
“Identical” means that all tables have identical
column and index information. You cannot merge tables in which the
columns are listed in a different order, do not have exactly the
same columns, or have the indexes in different order. However, any
or all of the tables can be compressed with
myisampack. See Section 8.2, “myisampack — Generate Compressed, Read-Only MyISAM Tables”.
Differences in table options such as
AVG_ROW_LENGTH, MAX_ROWS, or
PACK_KEYS do not matter.
When you create a MERGE table, MySQL creates
two files on disk. The files have names that begin with the table
name and have an extension to indicate the file type. An
.frm file stores the table definition, and an
.MRG file contains the names of the tables
that should be used as one. (Originally, all used tables had to be
in the same database as the MERGE table itself.
This restriction has been lifted as of MySQL 4.1.1.)
You can use SELECT, DELETE,
UPDATE, and (as of MySQL 4.0)
INSERT on the collection of tables. You must
have SELECT, UPDATE, and
DELETE privileges on the tables that you map to
a MERGE table.
If you DROP the MERGE table,
you are dropping only the MERGE specification.
The underlying tables are not affected.
When you create a MERGE table, you must specify
a
UNION=(
clause that indicates which tables you want to use as one. You can
optionally specify an list-of-tables)INSERT_METHOD option if
you want inserts for the MERGE table to take
place in the first or last table of the UNION
list. Use a value of FIRST or
LAST to cause inserts to be made in the first
or last table, respectively. If you do not specify an
INSERT_METHOD option or if you specify it with
a value of NO, attempts to insert records into
the MERGE table result in an error.
The following example shows how to create a
MERGE table:
mysql>CREATE TABLE t1 (->a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,->message CHAR(20));mysql>CREATE TABLE t2 (->a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,->message CHAR(20));mysql>INSERT INTO t1 (message) VALUES ('Testing'),('table'),('t1');mysql>INSERT INTO t2 (message) VALUES ('Testing'),('table'),('t2');mysql>CREATE TABLE total (->a INT NOT NULL AUTO_INCREMENT,->message CHAR(20), INDEX(a))->TYPE=MERGE UNION=(t1,t2) INSERT_METHOD=LAST;
Note that the a column is indexed in the
MERGE table, but is not declared as a
PRIMARY KEY as it is in the underlying
MyISAM tables. This is necessary because a
MERGE table cannot enforce uniqueness over the
set of underlying tables.
After creating the MERGE table, you can issue
queries that operate on the group of tables as a whole:
mysql> SELECT * FROM total;
+---+---------+
| a | message |
+---+---------+
| 1 | Testing |
| 2 | table |
| 3 | t1 |
| 1 | Testing |
| 2 | table |
| 3 | t2 |
+---+---------+
Note that you can also manipulate the .MRG
file directly from outside of the MySQL server:
shell>cd /shell>mysql-data-directory/current-databasels -1 t1 t2 > total.MRGshell>mysqladmin flush-tables
To remap a MERGE table to a different
collection of MyISAM tables, you can perform
one of the following:
DROPtheMERGEtable and re-create it.Use
ALTER TABLEto change the list of underlying tables.tbl_nameUNION=(...)Change the
.MRGfile and issue aFLUSH TABLEstatement for theMERGEtable and all underlying tables to force the storage engine to read the new definition file.
MERGE tables can help you solve the following
problems:
Easily manage a set of log tables. For example, you can put data from different months into separate tables, compress some of them with myisampack, and then create a
MERGEtable to use them as one.Obtain more speed. You can split a big read-only table based on some criteria, and then put individual tables on different disks. A
MERGEtable on this could be much faster than using the big table.Perform more efficient searches. If you know exactly what you are looking for, you can search in just one of the split tables for some queries and use a
MERGEtable for others. You can even have many differentMERGEtables that use overlapping sets of tables.Perform more efficient repairs. It is easier to repair individual tables that are mapped to a
MERGEtable than to repair a single large table.Instantly map many tables as one. A
MERGEtable need not maintain an index of its own because it uses the indexes of the individual tables. As a result,MERGEtable collections are very fast to create or remap. (Note that you must still specify the index definitions when you create aMERGEtable, even though no indexes are created.)If you have a set of tables that you join as a big table on demand or batch, you should instead create a
MERGEtable on them on demand. This is much faster and saves a lot of disk space.Exceed the file size limit for the operating system. Each
MyISAMtable is bound by this limit, but a collection ofMyISAMtables is not.You can create an alias or synonym for a
MyISAMtable by defining aMERGEtable that maps to that single table. There should be no really notable performance impact from doing this (only a couple of indirect calls andmemcpy()calls for each read).
The disadvantages of MERGE tables are:
You can use only identical
MyISAMtables for aMERGEtable.You cannot use a number of
MyISAMfeatures inMERGEtables. For example, you cannot createFULLTEXTindexes onMERGEtables. (You can, of course, createFULLTEXTindexes on the underlyingMyISAMtables, but you cannot search theMERGEtable with a full-text search.)If the
MERGEtable is non-temporary, all underlyingMyISAMtables have to be permanent, too. If theMERGEtable is temporary, theMyISAMtables can be any mix of temporary and non-temporary.MERGEtables use more file descriptors. If 10 clients are using aMERGEtable that maps to 10 tables, the server uses (10*10) + 10 file descriptors. (10 data file descriptors for each of the 10 clients, and 10 index file descriptors shared among the clients.)Key reads are slower. When you read a key, the
MERGEstorage engine needs to issue a read on all underlying tables to check which one most closely matches the given key. If you then do a read-next, theMERGEstorage engine needs to search the read buffers to find the next key. Only when one key buffer is used up does the storage engine need to read the next key block. This makesMERGEkeys much slower oneq_refsearches, but not much slower onrefsearches. See Section 7.2.1, “EXPLAINSyntax (Get Information About aSELECT)” for more information abouteq_refandref.
The following are known problems with MERGE
tables:
If you use
ALTER TABLEto change aMERGEtable to another table type, the mapping to the underlying tables is lost. Instead, the rows from the underlyingMyISAMtables are copied into the altered table, which is then assigned the new type.Before MySQL 4.1.1, all underlying tables and the
MERGEtable itself had to be in the same database.REPLACEdoes not work.You cannot use
DROP TABLE,ALTER TABLE,DELETE FROMwithout aWHEREclause,REPAIR TABLE,TRUNCATE TABLE,OPTIMIZE TABLE, orANALYZE TABLEon any of the tables that are mapped into an openMERGEtable. If you do so, theMERGEtable may still refer to the original table, which yields unexpected results. The easiest way to work around this deficiency is to issue aFLUSH TABLESstatement prior to performing any of these operations to ensure that noMERGEtables remain open.A
MERGEtable cannot maintainUNIQUEconstraints over the whole table. When you perform anINSERT, the data goes into the first or lastMyISAMtable (depending on the value of theINSERT_METHODoption). MySQL ensures that unique key values remain unique within thatMyISAMtable, but not across all the tables in the collection.Before MySQL 3.23.49,
DELETE FROMused without amerge_tableWHEREclause only clears the mapping for the table. That is, it incorrectly empties the.MRGfile rather than deleting records from the mapped tables.Using
RENAME TABLEon an activeMERGEtable may corrupt the table. This is fixed in MySQL 4.1.x.When you create a
MERGEtable, there is no check to insure that the underlying tables exist and have identical structures. When theMERGEtable is used, MySQL checks that the record length for all mapped tables is equal, but this is not foolproof. If you create aMERGEtable from dissimilarMyISAMtables, you are very likely to run into strange problems.The order of indexes in the
MERGEtable and its underlying tables should be the same. If you useALTER TABLEto add aUNIQUEindex to a table used in aMERGEtable, and then useALTER TABLEto add a non-unique index on theMERGEtable, the index ordering is different for the tables if there was already a non-unique index in the underlying table. (This is becauseALTER TABLEputsUNIQUEindexes before non-unique indexes to facilitate rapid detection of duplicate keys.) Consequently, queries on tables with such indexes may return unexpected results.DROP TABLEon a table that is in use by aMERGEtable does not work on Windows because theMERGEstorage engine's table mapping is hidden from the upper layer of MySQL. Since Windows does not allow the deletion of open files, you first must flush allMERGEtables (withFLUSH TABLES) or drop theMERGEtable before dropping the table.
For the MERGE storage engine, there's a
dedicated forum available on
http://forums.mysql.com/list.php?93.
The MEMORY storage engine creates tables with
contents that are stored in memory. Before MySQL 4.1,
MEMORY tables are called
HEAP tables. As of 4.1,
MEMORY is the preferred term, although
HEAP remains supported for backwards
compatibility.
Each MEMORY table is associated with one disk
file. The filename begins with the table name and has an extension
of .frm to indicate that it stores the table
definition.
To specify explicitly that you want a MEMORY
table, indicate that with an ENGINE or
TYPE table option:
CREATE TABLE t (i INT) ENGINE = MEMORY; CREATE TABLE t (i INT) TYPE = HEAP;
As indicated by their name, MEMORY tables are
stored in memory and use hash indexes by default. This makes them
very fast, and very useful for creating temporary tables. However,
when the server shuts down, all data stored in
MEMORY tables is lost. The tables themselves
continue to exist because their definitions are stored in
.frm files on disk, but they are empty when
the server restarts.
This example shows how you might create, use, and remove a
MEMORY table:
mysql>CREATE TABLE test TYPE=MEMORY->SELECT ip,SUM(downloads) AS down->FROM log_table GROUP BY ip;mysql>SELECT COUNT(ip),AVG(down) FROM test;mysql>DROP TABLE test;
MEMORY tables have the following
characteristics:
Space for
MEMORYtables is allocated in small blocks. Tables use 100% dynamic hashing for inserts. No overflow area or extra key space is needed. No extra space is needed for free lists. Deleted rows are put in a linked list and are reused when you insert new data into the table.MEMORYtables also have none of the problems commonly associated with deletes plus inserts in hashed tables.MEMORYtables allow up to 32 indexes per table and 16 columns per index. Previously, the maximum key length supported by this storage engine was 255 bytes; as of MySQL 4.1.13,MEMORYtables support a maximum key length of 500 bytes. (See Section D.1.14, “Changes in release 4.1.3 (28 Jun 2004: Beta)”.)Before MySQL 4.1, the
MEMORYstorage engine implements only hash indexes. From MySQL 4.1 on, hash indexes are still the default, but you can specify explicitly that aMEMORYtable index should be aHASHorBTREEby adding aUSINGclause as shown here:CREATE TABLE lookup (id INT, INDEX USING HASH (id)) ENGINE = MEMORY; CREATE TABLE lookup (id INT, INDEX USING BTREE (id)) ENGINE = MEMORY;General characteristics of B-tree and hash indexes are described in Section 7.4.5, “How MySQL Uses Indexes”.
You can have non-unique keys in a
MEMORYtable. (This is an uncommon feature for implementations of hash indexes.)As of MySQL 4.1, you can use
INSERT DELAYEDwithMEMORYtables. See Section 13.2.4.2, “INSERT DELAYEDSyntax”.If you have a hash index on a
MEMORYtable that has a high degree of key duplication (many index entries containing the same value), updates to the table that affect key values and all deletes are significantly slower. The degree of this slowdown is proportional to the degree of duplication (or, inversely proportional to the index cardinality). You can use aBTREEindex to avoid this problem.MEMORYtables use a fixed record length format.MEMORYdoesn't supportBLOBorTEXTcolumns.MEMORYdoesn't supportAUTO_INCREMENTcolumns before MySQL 4.1.0.Prior to MySQL 4.0.2,
MEMORYdoesn't support indexes on columns that can containNULLvalues.MEMORYtables are shared between all clients (just like any other non-TEMPORARYtable).MEMORYtable contents are stored in memory, which is a property thatMEMORYtables share with internal tables that the server creates on the fly while processing queries. However, the two types of tables differ in thatMEMORYtables are not subject to storage conversion, whereas internal tables are:If an internal table becomes too large, the server automatically converts it to an on-disk table. The size limit is determined by the value of the
tmp_table_sizesystem variable.MEMORYtables are never converted to disk tables. To ensure that you don't accidentally do anything foolish, you can set themax_heap_table_sizesystem variable to impose a maximum size onMEMORYtables. For individual tables, you can also specify aMAX_ROWStable option in theCREATE TABLEstatement.
The server needs sufficient memory to maintain all
MEMORYtables that are in use at the same time.To free memory used by a
MEMORYtable when you no longer require its contents, you should executeDELETE FROMorTRUNCATE TABLE, or remove the table altogether (usingDROP TABLE).If you want to populate a
MEMORYtable when the MySQL server starts, you can use the--init-fileoption. For example, you can put statements such asINSERT INTO ... SELECTorLOAD DATA INFILEinto this file in order to load the table from a persistent data source. See Section 5.2.1, “mysqld Command-Line Options” and Section 13.2.5, “LOAD DATA INFILESyntax”.If you are using replication, the master server's
MEMORYtables become empty when it is shut down and restarted. However, a slave is not aware that these tables have become empty, so it returns out-of-date content if you select data from them. Beginning with MySQL 4.0.18, when aMEMORYtable is used on the master for the first time since the master was started, aDELETE FROMstatement is written to the master's binary log automatically, thus synchronizing the slave to the master again. Note that even with this strategy, the slave still has outdated data in the table during the interval between the master's restart and its first use of the table. However, if you use the--init-fileoption to populate theMEMORYtable on the master at startup, it ensures that this time interval is zero.The memory needed for one row in a
MEMORYtable is calculated using the following expression:SUM_OVER_ALL_BTREE_KEYS(
max_length_of_key+ sizeof(char*) * 4) + SUM_OVER_ALL_HASH_KEYS(sizeof(char*) * 2) + ALIGN(length_of_row+1, sizeof(char*))ALIGN()represents a round-up factor to cause the row length to be an exact multiple of thecharpointer size.sizeof(char*)is 4 on 32-bit machines and 8 on 64-bit machines.
For the MEMORY storage engine, there's a
dedicated forum available on
http://forums.mysql.com/list.php?92.
Sleepycat Software has provided MySQL with the Berkeley DB
transactional storage engine. This storage engine typically is
called BDB for short. Support for the
BDB storage engine is included in MySQL source
distributions starting from version 3.23.34a and is activated in
MySQL-Max binary distributions.
BDB tables may have a greater chance of
surviving crashes and are also capable of
COMMIT and ROLLBACK
operations on transactions. The MySQL source distribution comes
with a BDB distribution that is patched to make
it work with MySQL. You cannot use a non-patched version of
BDB with MySQL.
We at MySQL AB work in close cooperation with Sleepycat to keep the quality of the MySQL/BDB interface high. (Even though Berkeley DB is in itself very tested and reliable, the MySQL interface is still considered gamma quality. We continue to improve and optimize it.)
When it comes to support for any problems involving
BDB tables, we are committed to helping our
users locate the problem and create reproducible test cases. Any
such test case is forwarded to Sleepycat, who in turn help us find
and fix the problem. As this is a two-stage operation, any
problems with BDB tables may take a little
longer for us to fix than for other storage engines. However, we
anticipate no significant difficulties with this procedure because
the Berkeley DB code itself is used in many applications other
than MySQL.
For general information about Berkeley DB, please visit the Sleepycat Web site, http://www.sleepycat.com/.
Currently, we know that the BDB storage
engine works with the following operating systems:
Linux 2.x Intel
Sun Solaris (SPARC and x86)
FreeBSD 4.x/5.x (x86, sparc64)
IBM AIX 4.3.x
SCO OpenServer
SCO UnixWare 7.1.x
Windows NT/2000/XP
BDB does not work with
the following operating systems:
Linux 2.x Alpha
Linux 2.x AMD64
Linux 2.x IA-64
Linux 2.x s390
Mac OS X
Note: The preceding lists are not complete. We update them as we receive more information.
If you build MySQL from source with support for
BDB tables, but the following error occurs
when you start mysqld, it means
BDB is not supported for your architecture:
bdb: architecture lacks fast mutexes: applications cannot be threaded Can't init databases
In this case, you must rebuild MySQL without
BDB table support or start the server with
the --skip-bdb option.
If you have downloaded a binary version of MySQL that includes
support for Berkeley DB, simply follow the usual binary
distribution installation instructions. (MySQL-Max distributions
include BDB support.)
If you build MySQL from source, you can enable
BDB support by running
configure with the
--with-berkeley-db option in addition to any
other options that you normally use. Download a distribution for
MySQL 3.23.34 or newer, change location into its top-level
directory, and run this command:
shell> ./configure --with-berkeley-db [other-options]
For more information, see Section 2.7, “Installing MySQL on Other Unix-Like Systems”, Section 5.1.2, “The mysqld-max Extended MySQL Server”, and Section 2.8, “MySQL Installation Using a Source Distribution”.
The following options to mysqld can be used
to change the behavior of the BDB storage
engine:
--bdb-home=pathThe base directory for
BDBtables. This should be the same directory you use for--datadir.--bdb-lock-detect=methodThe
BDBlock detection method. The option value should beDEFAULT,OLDEST,RANDOM, orYOUNGEST.--bdb-logdir=pathThe
BDBlog file directory.--bdb-no-recoverDo not start Berkeley DB in recover mode.
--bdb-no-syncDon't synchronously flush the
BDBlogs. This option is deprecated as of MySQL 4.0.18; use--skip-sync-bdb-logsinstead (see the description for--sync-bdb-logs).--bdb-shared-dataStart Berkeley DB in multi-process mode. (Do not use
DB_PRIVATEwhen initializing Berkeley DB.)--bdb-tmpdir=pathThe
BDBtemporary file directory.--skip-bdbDisable the
BDBstorage engine.--sync-bdb-logsSynchronously flush the
BDBlogs. This option is enabled by default; use--skip-sync-bdb-logsto disable it. This option was added in MySQL 4.0.18.
See Section 5.2.1, “mysqld Command-Line Options”.
If you use the --skip-bdb option, MySQL does
not initialize the Berkeley DB library and this saves a lot of
memory. However, if you use this option, you cannot use
BDB tables. If you try to create a
BDB table, MySQL creates a
MyISAM table instead.
Normally, you should start mysqld without the
--bdb-no-recover option if you intend to use
BDB tables. However, this may cause problems
when you try to start mysqld if the
BDB log files are corrupted. See
Section 2.9.2.3, “Starting and Troubleshooting the MySQL Server”.
With the bdb_max_lock variable, you can
specify the maximum number of locks that can be active on a
BDB table. The default is 10,000. You should
increase this if errors such as the following occur when you
perform long transactions or when mysqld has
to examine many rows to execute a query:
bdb: Lock table is out of available locks Got error 12 from ...
You may also want to change the
binlog_cache_size and
max_binlog_cache_size variables if you are
using large multiple-statement transactions. See
Section 5.10.4, “The Binary Log”.
See also Section 5.2.3, “Server System Variables”.
Each BDB table is stored on disk in two
files. The files have names that begin with the table name and
have an extension to indicate the file type. An
.frm file stores the table definition, and
a .db file contains the table data and
indexes.
To specify explicitly that you want a BDB
table, indicate that with an ENGINE or
TYPE table option:
CREATE TABLE t (i INT) ENGINE = BDB; CREATE TABLE t (i INT) TYPE = BDB;
BerkeleyDB is a synonym for
BDB in the ENGINE or
TYPE option.
The BDB storage engine provides transactional
tables. The way you use these tables depends on the autocommit
mode:
If you are running with autocommit enabled (which is the default), changes to
BDBtables are committed immediately and cannot be rolled back.If you are running with autocommit disabled, changes do not become permanent until you execute a
COMMITstatement. Instead of committing, you can executeROLLBACKto forget the changes.You can start a transaction with the
BEGIN WORKstatement to suspend autocommit, or withSET AUTOCOMMIT=0to disable autocommit explicitly.
See Section 13.4.1, “START TRANSACTION, COMMIT, and ROLLBACK Syntax”.
The BDB storage engine has the following
characteristics:
BDBtables can have up to 31 indexes per table, 16 columns per index, and a maximum key size of 1024 bytes (500 bytes before MySQL 4.0).MySQL requires a
PRIMARY KEYin eachBDBtable so that each row can be uniquely identified. If you don't create one explicitly, MySQL creates and maintains a hiddenPRIMARY KEYfor you. The hidden key has a length of five bytes and is incremented for each insert attempt. This key does not appear in the output ofSHOW CREATE TABLEorDESCRIBE.The
PRIMARY KEYis faster than any other index, because thePRIMARY KEYis stored together with the row data. The other indexes are stored as the key data + thePRIMARY KEY, so it's important to keep thePRIMARY KEYas short as possible to save disk space and get better speed.This behavior is similar to that of
InnoDB, where shorter primary keys save space not only in the primary index but in secondary indexes as well.If all columns you access in a
BDBtable are part of the same index or part of the primary key, MySQL can execute the query without having to access the actual row. In aMyISAMtable, this can be done only if the columns are part of the same index.Sequential scanning is slower than for
MyISAMtables because the data inBDBtables is stored in B-trees and not in a separate data file.Key values are not prefix- or suffix-compressed like key values in
MyISAMtables. In other words, key information takes a little more space inBDBtables compared toMyISAMtables.There are often holes in the
BDBtable to allow you to insert new rows in the middle of the index tree. This makesBDBtables somewhat larger thanMyISAMtables.SELECT COUNT(*) FROMis slow fortbl_nameBDBtables, because no row count is maintained in the table.The optimizer needs to know the approximate number of rows in the table. MySQL solves this by counting inserts and maintaining this in a separate segment in each
BDBtable. If you don't issue a lot ofDELETEorROLLBACKstatements, this number should be accurate enough for the MySQL optimizer. However, MySQL stores the number only on close, so it may be incorrect if the server terminates unexpectedly. It should not be fatal even if this number is not 100% correct. You can update the row count by usingANALYZE TABLEorOPTIMIZE TABLE. See Section 13.5.2.1, “ANALYZE TABLESyntax” and Section 13.5.2.5, “OPTIMIZE TABLESyntax”.Internal locking in
BDBtables is done at the page level.LOCK TABLESworks onBDBtables as with other tables. If you do not useLOCK TABLES, MySQL issues an internal multiple-write lock on the table (a lock that does not block other writers) to ensure that the table is properly locked if another thread issues a table lock.To be able to roll back transactions, the
BDBstorage engine maintains log files. For maximum performance, you can use the--bdb-logdiroption to place theBDBlogs on a different disk than the one where your databases are located.MySQL performs a checkpoint each time a new
BDBlog file is started, and removes anyBDBlog files that are not needed for current transactions. You can also useFLUSH LOGSat any time to checkpoint the Berkeley DB tables.For disaster recovery, you should use table backups plus MySQL's binary log. See Section 5.8.1, “Database Backups”.
Warning: If you delete old log files that are still in use,
BDBis not able to do recovery at all and you may lose data if something goes wrong.Applications must always be prepared to handle cases where any change of a
BDBtable may cause an automatic rollback and any read may fail with a deadlock error.If you get a full disk with a
BDBtable, you get an error (probably error 28) and the transaction should roll back. This contrasts withMyISAMandISAMtables, for which mysqld waits for sufficient free disk space before continuing.
Opening many
BDBtables at the same time may be quite slow. If you are going to useBDBtables, you should not have a very large table cache (for example, with a size larger than 256) and you should use the--no-auto-rehashoption when you use the mysql client.SHOW TABLE STATUSdoes not provide some information forBDBtables:mysql>
SHOW TABLE STATUS LIKE 'bdbtest'\G*************************** 1. row *************************** Name: bdbtest Engine: BerkeleyDB Version: 10 Row_format: Dynamic Rows: 154 Avg_row_length: 0 Data_length: 0 Max_data_length: 0 Index_length: 0 Data_free: 0 Auto_increment: NULL Create_time: NULL Update_time: NULL Check_time: NULL Collation: latin1_swedish_ci Checksum: NULL Create_options: Comment:Optimize performance.
Change to use no page locks for table scanning operations.
The following list indicates restrictions that you must observe
when using BDB tables:
Each
BDBtable stores in the.dbfile the path to the file as it was created. This was done enable detection of locks in a multi-user environment that supports symlinks. As a consequence of this, it is not possible to moveBDBtable files from one database directory to another.When making backups of
BDBtables, you must either use mysqldump or else make a backup that includes the files for eachBDBtable (the.frmand.dbfiles) as well as theBDBlog files. TheBDBstorage engine stores unfinished transactions in its log files and requires them to be present when mysqld starts. TheBDBlogs are the files in the data directory with names of the formlog.XXXXXXXXXX(ten digits).If a column that allows
NULLvalues has a unique index, only a singleNULLvalue is allowed. This differs from other storage engines.
If the following error occurs when you start mysqld after upgrading, it means that the new
BDBversion doesn't support the old log file format:bdb: Ignoring log file: .../log.XXXXXXXXXX: unsupported log version #
In this case, you must delete all
BDBlogs from your data directory (the files with names that have the formatlog.XXXXXXXXXX) and restart mysqld. We also recommend that you then use mysqldump --opt to dump yourBDBtables, drop the tables, and restore them from the dump file.If autocommit mode is disabled and you drop a
BDBtable that is referenced in another transaction, you may get error messages of the following form in your MySQL error log:001119 23:43:56 bdb: Missing log fileid entry 001119 23:43:56 bdb: txn_abort: Log undo failed for LSN: 1 3644744: InvalidThis is not fatal, but until the problem is fixed, we recommend that you not drop
BDBtables except while autocommit mode is enabled. (The fix is not trivial.)
The EXAMPLE storage engine was added in MySQL
4.1.3. It is a “stub” engine that does nothing. Its
purpose is to serve as an example in the MySQL source code that
illustrates how to begin writing new storage engines. As such, it
is primarily of interest to developers.
To examine the source for the EXAMPLE engine,
look in the sql/examples directory of a
source distribution for MySQL 4.1.3 or newer.
To enable this storage engine, use the
--with-example-storage-engine option to
configure when you build MySQL.
When you create an EXAMPLE table, the server
creates a table definition file in the database directory. The
file begins with the table name and has an
.frm extension. No other files are created.
No data can be stored into the table or retrieved from it.
mysql>CREATE TABLE test (i INT) ENGINE = EXAMPLE;Query OK, 0 rows affected (0.78 sec) mysql>INSERT INTO test VALUES(1),(2),(3);ERROR 1031 (HY000): Table storage engine for 'test' doesn't have this option mysql>SELECT * FROM test;Empty set (0.31 sec)
The EXAMPLE storage engine does not support
indexing.
The ARCHIVE storage engine was added in MySQL
4.1.3. It is used for storing large amounts of data without
indexes in a very small footprint.
To enable this storage engine, use the
--with-archive-storage-engine option to
configure when you build MySQL. You can see if
this storage engine is available with this statement:
mysql> SHOW VARIABLES LIKE 'have_archive';
When you create an ARCHIVE table, the server
creates a table definition file in the database directory. The
file begins with the table name and has an
.frm extension. The storage engine creates
other files, all having names beginning with the table name. The
data and metadata files have extensions of
.ARZ and .ARM. A
.ARN file may appear during optimization
operations.
The ARCHIVE engine supports only
INSERT and SELECT (no
deletes, replaces, or updates). It does support ORDER
BY operations, BLOB fields, and
basically all data types except geometry data types (see
Section 17.4.1, “MySQL Spatial Data Types”). The
ARCHIVE engine uses row-level locking.
Storage: Records are compressed
as they are inserted. The ARCHIVE engine uses
zlib lossless data
compression. Use of OPTIMIZE TABLE can analyze
the table and pack it into a smaller format (for a reason to use
OPTIMIZE TABLE, see below). There are several
types of insertions that are used:
A straight
INSERTjust pushes rows into a compression buffer, and that buffer flushes as it needs. The insertion into the buffer is protected by a lock. ASELECTforces a flush to occur, unless the only insertions that have come in wereINSERT DELAYED(those flush as need be). See Section 13.2.4.2, “INSERT DELAYEDSyntax”.A bulk insert is only visible after it completes, unless other inserts occur at the same time, in which case it can be seen partially. A
SELECTnever causes a flush of a bulk insert unless a normal insert occurs while it is loading.
Retrieval: On retrieval, records
are uncompressed on demand; there is no row cache. A
SELECT operation performs a complete table
scan: When a SELECT occurs, it finds out how
many rows are currently available and reads that number of rows.
SELECT is performed as a consistent read. Note
that lots of SELECT statements during insertion
can deteriorate the compression, unless only bulk or delayed
inserts are used. To fix any compression issues that have occurred
you can always do an OPTIMIZE TABLE
(REPAIR TABLE also is supported). The number of
rows in ARCHIVE tables reported by
SHOW TABLE STATUS is always accurate. See
Section 13.5.2.6, “REPAIR TABLE Syntax”, Section 13.5.2.5, “OPTIMIZE TABLE Syntax”,
Section 13.5.4.18, “SHOW TABLE STATUS Syntax”.
For the ARCHIVE storage engine, there's a
dedicated forum available on
http://forums.mysql.com/list.php?112.
The CSV storage engine was added in MySQL
4.1.4. This engine stores data in text files using
comma-separated-values format.
To enable this storage engine, use the
--with-csv-storage-engine option to
configure when you build MySQL.
When you create a CSV table, the server creates
a table definition file in the database directory. The file begins
with the table name and has an .frm
extension. The storage engine also creates a data file. Its name
begins with the table name and has a .CSV
extension. The data file is a plain text file. When you store data
into the table, the storage engine saves it into the data file in
CSV format.
mysql>CREATE TABLE test(i INT, c CHAR(10)) ENGINE = CSV;Query OK, 0 rows affected (0.12 sec) mysql>INSERT INTO test VALUES(1,'record one'),(2,'record two');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM test;+------+------------+ | i | c | +------+------------+ | 1 | record one | | 2 | record two | +------+------------+ 2 rows in set (0.00 sec)
If you examine the test.CSV file in the
database directory created by executing the preceding statements,
its contents should look like this:
"1","record one" "2","record two"
The CSV storage engine does not support
indexing.
The BLACKHOLE storage engine was added in MySQL
4.1.11. This engine acts as a “black hole” that
accepts data but throws it away and does not store it. Retrievals
always return the empty set:
mysql>CREATE TABLE test(i INT, c CHAR(10)) ENGINE = BLACKHOLE;Query OK, 0 rows affected (0.03 sec) mysql>INSERT INTO test VALUES(1,'record one'),(2,'record two');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM test;Empty set (0.00 sec)
When you create a BLACKHOLE table, the server
creates a table definition file in the database directory. The
file begins with the table name and has an
.frm extension. There are no other files
associated with the table.
The BLACKHOLE storage engine supports all kinds
of indexing.
To enable this storage engine, use the
--with-blackhole-storage-engine option to
configure when you build MySQL. The
BLACKHOLE storage engine is available in
MySQL-supplied server binaries beginning with MySQL 4.1.12; you
can determine whether or not your version supports this engine by
viewing the output of SHOW ENGINES or
SHOW VARIABLES LIKE 'have%'.
Inserts into a BLACKHOLE table do not store any
data, but if the binary log is enabled, the SQL statements are
logged (and replicated to slave servers). This can be useful as a
repeater or filter mechanism. For example, suppose that your
application requires slave-side filtering rules, but transfering
all binlog data to the slave first results in too much traffic. In
such a case, it is possible to set up on the master host a
“dummy” slave process whose default storage engine is
BLACKHOLE, depicted as follows:
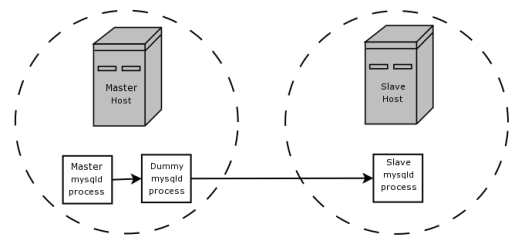
The master writes to its binary log. The “dummy”
mysqld process acts as a slave, applying the
desired combination of replicate-do and
replicate-ignore rules, and writes a new,
filtered binlog of its own. (See
Section 6.8, “Replication Startup Options”.) This filtered log is
provided to the slave.
Since the dummy process does not actually store any data, there is
little processing over head incurred by running the additional
mysqld process on the replication master host.
This type of setup can be repeated with additional replication
slaves.
Other possible uses for the BLACKHOLE storage
engine include:
Verification of dumpfile syntax.
Measurement of the overhead from binary logging, by comparing performance using
BLACKHOLEwith and without binary logging enabled.since
BLACKHOLEis essentially a “no-op” storage engine, it could be used for finding performance bottlenecks not related to the storage engine itself.
The original storage engine in MySQL was the
ISAM engine. It was the only storage engine
available until MySQL 3.23, when the improved
MyISAM engine was introduced as the default.
ISAM is deprecated. As of MySQL 4.1, it's
included in the source but not enabled in binary distributions. It
is not available in MySQL 5.0. Embedded MySQL server versions do
not support ISAM tables by default.
Due to the deprecated status of ISAM, and
because MyISAM is an improvement over
ISAM, you are advised to convert any remaining
ISAM tables to MyISAM as
soon as possible. To convert an ISAM table to a
MyISAM table, use an ALTER
TABLE statement:
mysql> ALTER TABLE tbl_name TYPE = MYISAM;
For more information about MyISAM, see
Section 14.1, “The MyISAM Storage Engine”.
Each ISAM table is stored on disk in three
files. The files have names that begin with the table name and
have an extension to indicate the file type. An
.frm file stores the table definition. The
data file has an .ISD extension. The index
file has an .ISM extension.
ISAM uses B-tree indexes.
You can check or repair ISAM tables with the
isamchk utility. See
Section 5.8.5.6, “Using myisamchk for Crash Recovery”.
ISAM has the following properties:
Compressed and fixed-length keys
Fixed and dynamic record length
16 indexes per table, with 16 key parts per key
Maximum key length 256 bytes (default)
Data values are stored in machine format; this is fast, but machine/OS dependent
Many of the properties of MyISAM tables are
also true for ISAM tables. However, there are
also many differences. The following list describes some of the
ways that ISAM is distinct from
MyISAM:
Not binary portable across OS/platforms.
Can't handle tables larger than 4GB.
Only supports prefix compression on strings.
Smaller (more restrictive) key limits.
Dynamic tables become more fragmented.
Doesn't support
MERGEtables.Tables are checked and repaired with isamchk rather than with myisamchk.
Tables are compressed with pack_isam rather than with myisampack.
Cannot be used with the
BACKUP TABLEorRESTORE TABLEbackup-related statements.Cannot be used with the
CHECK TABLE,REPAIR TABLE,OPTIMIZE TABLE, orANALYZE TABLEtable-maintenance statements.No support for full-text searching or spatial data types.
No support for multiple character sets per table.
Indexes cannot be assigned to specific key caches.